A list of things to think of before deciding to use a distributed cache
Choosing the right cache software for your web application is not an easy job. The first and most important question that you have to ask yourself is if you actually need a cache in your application. But what exactly is a cache and how an application can profit or not from its use?
A cache is a software component that is used for storing data in memory (RAM) in order to provide faster accesses to this data. Using a cache you can save time and I/O operations, since you do not access the data stored in other slower types of storages such as relational databases or XML files in a hard disk drive.
Most of the cache implementations provide a simple key-value storage, where the key is unique in the cache. The value can be then extracted by using the unique key. The type of the value can be from a simple primitive value (boolean, string, number) to a complex object. In both type-cases you have to serialize the key-value pair and most of the times store it a simple string in the cache (continue reading for more information about serialization and deserialization).
When we talk about large web application, for example the ones that hosted in the cloud and serve thousands of requests pair day, then when we think about a cache software, this software has to be a distributed cache, since the application are also distributed. We can define two main types of caches:
-
Local cache: This is type of cache is used for example from your web browser. Only your browser can access the data of this cache and serve it back to you. This cache is used mostly for storing static files such as images, JavaScript or CSS files.
-
Distributed cache: A cache which is available and accessible to multiple users. A common scenario for using a distributed cache is an application that its users access common business data. This type of cache is usually installed as a stand alone software in one or more computers (nodes), together these computers form a cluster and they can be scattered in different locations for even faster access. A distributed cache can be used in cooperation with the previous mentioned centralized cache.
The data stored in such a cache is most of the times data retrieved from a database. New user requests that access common data, do not have to query the database again. The main question you have to ask yourself before deciding for a distributed cache is whether you really have such business data that can be accessed from multiple clients or not. It makes no sense to store data in a cache that are not going to be used multiple times from multiple users and in that case you better have to stick with the traditional server-database architecture.
Well known examples of distributed caches are the AppFabric cache from Microsoft and the open source cache Redis.
In order to get a better understanding about the architecture of a web application that use a client-server structure together with a distributed cache, consider the following simple diagram:
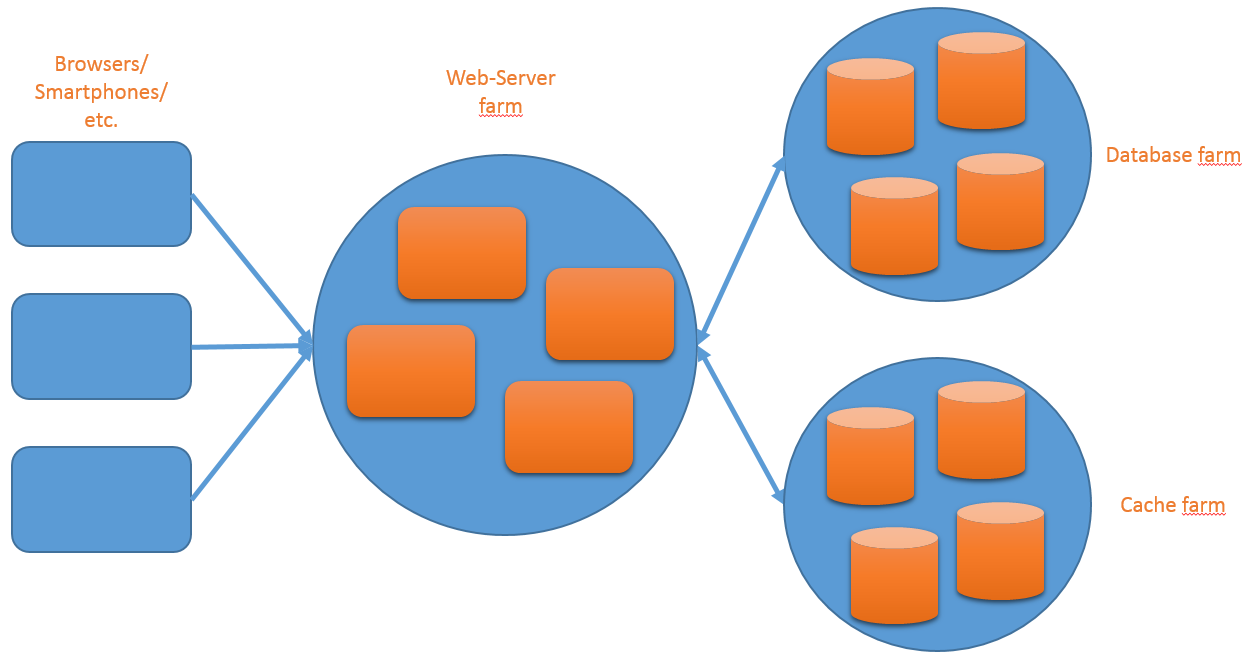
Since this article focuses on the distributed caches I am going to provide you with some important features that you have to consider if the cache software your selected, support.
-
Retry strategy:
There is always the possibility that a request sent to your cache might not succeed or return no answer. The reason can be a technical problem such as temporary unavailability or a high load of requests that your distributed cache has to answer. It is important that the cache supports a logic for automatically retrying the failed requests. In the context of the AppFabric cache this logic is called Transient Fault Handling and you can with code or with settings define a specific repeat-strategy for failed requests such as the repeat-time intervals, the times of repetition till aborting the retry logic, the time till the next repetition, etc..
-
Always running mode/ No loss of information:
Your distributed cache should store the data in a way that assures that a failed cache node (a node can be for example a physical computer that hosts your cache) will not result to losing data.
A safety net can be achieved by duplicating the stored data into multiple cache nodes. It is the responsibility of the cache software to make this duplication automatically and transparent to the user. In that case when a cache node fails, its data are not get lost since it is duplicated into a second or even more nodes. Till the failed node is brought back online, the remaining nodes duplicate again the data of the second back up node, so that it is always assured from the cache that a stored information is saved in at least two nodes. The AppFabric cache names this features high availability.
-
Serialization/ Deserialization of data:
Consider the following questions when you need to decide based on the way your cache serializes/ deserializes data:
-
Do you want to store complex objects or files, such as images, in the cache? Can the selected cache software serialize, store and then deserialize these types? Redis support for example complex data structures such as lists or hashsets:
// cache is the Redis cache instance await cache.ListLeftPushAsync("list1", "value 1"); await cache.ListLeftPushAsync("list1", "value 2"); -
Do you not only want to use strings as keys but also other data types such as byte arrays? Redis support byte arrays as type of your keys.
-
How fast is the serialization and deserialization of the stored data in your cache? Is this performance greater than the performance you would have if you simple used a relational database without any cache between the application and the database?
-
Can you set or get data from the cache only synchronously or it is also possible to do the operations asynchronously? In Redis an asynchronous call to set and get a key-value pair would look like following and would not block the execution of your code:
// cache is the Redis cache instance await cache.StringSetAsync("key1", "value1"); var val = await cache.StringGetAsync("key1");
-
-
Easiness of configuration:
Before deciding for a cache software take a look at the supported settings and parametrization options.
- Can you achieve the operations you want with the provided settings?
- Is it easy to change a setting of your new cache, for example add a new node to the cluster?
- Do you have to use a command prompt and write commands or your cache comes with a friendly user interface for tweaking its settings?
- Does your cache provide you any meta information about the stored data? For example how many objects does the cache contain or of what type.
-
Level of distribution:
How distributed has your distributed cache has to be? Do you have dedicated server (nodes) for your cache or you want to use the cloud and scale based on the requests? AppFabric and Redis support both ways and both can be hosted in the Azure cloud from Microsoft.
-
Define expiration dates for the stored objects:
Even when you use a cloud solution for your cache, the available storage for the stored data is finite. This means that you will have to manage the stored data in your cache and often you will have to delete data that are not any more needed or have not been used for a long period of time. By doing this way you can free storage and also reduce the searching time that your cache has to invest in order to find a searched key inside the cache.
What is your strategy concerning the data period your data can stay in the cache?
-
Do you want the stored objects to refresh their expiration period (sliding expiration) every time you access them with a get operation?
-
Or do you want to define an expiration date the first time you store a key-value pair into the cache and after that do not refresh this date even when you continue to access this specific key-value pair?
-
Apart from the previous strategies, many caches implement their own eviction strategies, such as the Last Recent Used (LRU) eviction that can be found both in AppFabric and in Redis.
-
Choosing a cache software is an important architectural decision that you have to make if your application keeps getting bigger and bigger and you have to deal with thousands of user requests pair day.
Drop me a wire if you have any questions, I would be happy to assist you with questions concerning the AppFabric or the Redis caches.